Keystroke Dynamics - Lab vs Field Data
Accompaniment to "TITLE" (CONF-DATE)
Author: Vrishab Commuri and Roy Maxion (Contact Me)
Contents:
This webpage presents two benchmark data sets for keystroke dynamics. It is a supplement to the paper "TITLE," by Vrishab Commuri and Roy Maxion, published in the proceedings of the CONF DATE conference [1]. The webpage is organized as follows:
- 1. Introduction: About this webpage
- 2. The Datasets: Two datasets, one collected in our lab and one collected in the field, each containing timing data for 100 unique subjects.
- 3. Contrasting Lab and Field Data: Key differences between lab and field data.
- 4. Lab vs Field Impact on Classification: Error-rate and misclassification results for the detectors: does lab vs field matter?
- 5. References: Relevant material and acknowledgments
Sections 1 – 4 each consist of a brief explanation of their contents, followed by a list of common questions that provide more detail about the material. Click on a question to show the answer, or display all answers by clicking on:
- SHOW / HIDE answers to all questions below.
1. Introduction
On this webpage, we share the data, scripts, and results of our evaluation so that other researchers can use the data, reproduce our results, and extend them; or, use the data for investigations of related topics, such as intrusion, masquerader or insider detection. We hope these resources will be useful to the research community.
Common questions:
- Q1-1: What is keystroke dynamics (or keystroke biometrics)?
- Q1-2: What is your paper about? What is this webpage for?
- Q1-3: Where can I find a copy of the paper?
- Q1-4: How would I cite this webpage in a publication?
Our intent with this webpage is to share our resources—the typing data, evaluation scripts, and the table of results—with the research community, and to answer questions that they (or you) might have.
2. The Datasets
This section presents two datasets: one collected in our lab and one collected in the field. The data for both consist of keystroke-timing information from 100 subjects
(typists), each typing a password (.tie5Roanl) 400 times.
-
Lab:
-
lab_dataset.txt(Fixed-width format) ................... MD5 hash = ?? -
lab_dataset.csv(Comma-separated-value format) MD5 hash = ?? lab_dataset.xls(Excel format) ............................. MD5 hash = ??
-
Field:
-
field_dataset.txt(Fixed-width format) ................... MD5 hash = ?? -
field_dataset.csv(Comma-separated-value format) MD5 hash = ?? field_dataset.xls(Excel format) ............................. MD5 hash = ??
Common questions:
- Q2-1: How were the data collected?
- Q2-2: How do I read the data into R / Matlab / Weka / Excel / ...?The data are provided in three different formats to make it easier for researchers visiting this page to view and manipulate the data. In all its forms, the data are organized into a table, but different applications are better suited to different formats.
(R): In the fixed-width format, the columns of the table are separated by one or more spaces so that the information in each column is aligned vertically. This format is easy to read in a standard web browser or document editor with a fixed width font. It can also be read by the standard data-input mechanisms of the statistical-programming environment R. Specifically, theread.tablecommand can be used to read the data into a structure called adata.frame:
X <-read.table( 'DSL-StrongPasswordData.txt', header=TRUE )
(Matlab and Weka): In the comma-separated-value format, the columns of the table are separated by commas. This format is commonly read by most data-analysis packages (e.g., Matlab). The Weka data-mining software has collected many machine-learning algorithms that might be brought to bear on the keystroke-dynamics data. While Weka encourages the use of its own ARFF data-input format, a researcher could convert a CSV into an ARFF-formatted file by prepending the appropriate header information.
(Excel): In the Microsoft Excel binary-file format, the columns of the table are encoded as a standard Excel spreadsheet. This format can be used by researchers wishing to bring Excel's data analysis and graphing capabilities to bear on the data.
By making the data available in these three formats, we hope to make it easier for other researchers to use their preferred data-analysis tools. In our own research, we use the fixed-width format and the R statistical-programming environment. - Q2-3: How are the data structured? What do the column names mean? (And why aren't the subject IDs consecutive?)
For complete details of our data collection methodology, we refer readers to our original paper [1]. A brief summary of our methodology follows.
Lab:We built a keystroke data-collection apparatus consisting of: (1) a laptop running Windows XP; (2) a Windows software application for presenting stimuli to the subjects, and for recording their keystrokes; and (3) an external reference timer for timestamping those keystrokes. The software presents the subject with the password to be typed. As the subject types the password, it is checked for correctness. If the subject makes a typographical error, the application prompts the subject to retype the password. In this manner, we record timestamps for 50 correctly typed passwords in each session.
Whenever the subject presses or releases a key, the software application records the event (i.e., keydown or keyup), the name of the key involved, and a timestamp for the moment at which the keystroke event occurred. An external reference clock was used to generate highly accurate timestamps. The reference clock was demonstrated to be accurate to within ±200 microseconds (by using a function generator to simulate key presses at fixed intervals).
We recruited 100 subjects (typists) from within a university community.
All subjects typed the same password, and each subject typed the
password 400 times over 8 sessions (50 repetitions per session). They
waited at least one day between sessions, to capture some of the
day-to-day variation of each subject's typing. The password
(.tie5Roanl) was chosen to be representative of a strong
10-character password.
The raw records of all the subjects' keystrokes and timestamps were analyzed to create a password-timing table. The password-timing table encodes the timing features for each of the 400 passwords that each subject typed.
Field:The same Windows application used to collect data for our lab dataset was adapted to run on the personal computer of each subject in our field dataset. Keystrokes were timestamped using two onboard timers available to Windows programs: the Query Performance Counter (QPC) for high-resolution timestamps and the Tick Timer for standard, low-resolution timestamps. Only timing data from the QPC is presented in the field dataset; the Tick Timer timestamps were used for sanity-checking our results.
We recruited 100 subjects from various university communities. All 100
subjects are distinct from the subjects in the lab dataset—there are no
subjects who contributed to both datasets. As in the lab dataset, all subjects
typed the same password (.tie5Roanl), and each subject typed the
password 400 times over 8 sessions (50 repetitions per session).
The password-timing table for the field data was generated from the raw data in the same manner as the password-timing table for the lab data. Likewise, the field data password-timing table encodes the timing features for each of the 400 passwords that each subject typed.
The data are arranged as a table with 34 columns. Each row of data corresponds to the timing information for a single repetition of the password by a single subject. The first column, subject, is a unique identifier for each subject (e.g.,
s002 or
s057). Even though the data set contains 51 subjects,
the identifiers do not range from s001
to s051; subjects have been assigned unique IDs across a
range of keystroke experiments, and not every subject participated in
every experiment. For instance, Subject 1 did not perform the
password typing task and so s001 does not appear in the
data set. The second column, sessionIndex, is the session in
which the password was typed (ranging from 1 to 8). The third
column, rep, is the repetition of the password within the
session (ranging from 1 to 50).The remaining 31 columns present the timing information for the password. The name of the column encodes the type of timing information. Column names of the form
H.key
designate a hold time for the named key (i.e., the time from when
key was pressed to when it was released). Column names of the
form DD.key1.key2 designate a
keydown-keydown time for the named digraph (i.e., the time from when
key1 was pressed to when key2 was pressed). Column
names of the form UD.key1.key2 designate a
keyup-keydown time for the named digraph (i.e., the time from when
key1 was released to when key2 was pressed). Note that
UD times can be negative, and that H times
and UD times add up to DD times.Consider the following one-line example of what you will see in the data:
subject sessionIndex rep H.period DD.period.t UD.period.t ...
s002 1 1 0.1491 0.3979 0.2488 ...
The example presents typing data for subject 2, session 1, repetition
1. The period key was held down for 0.1491 seconds
(149.1 milliseconds); the time between pressing the
period key and the t key (keydown-keydown
time) was 0.3979 seconds; the time between releasing the
period and pressing the t key (keyup-keydown
time) was 0.2488 seconds; and so on.
3. Contrasting Lab and Field Data
USB Polling:
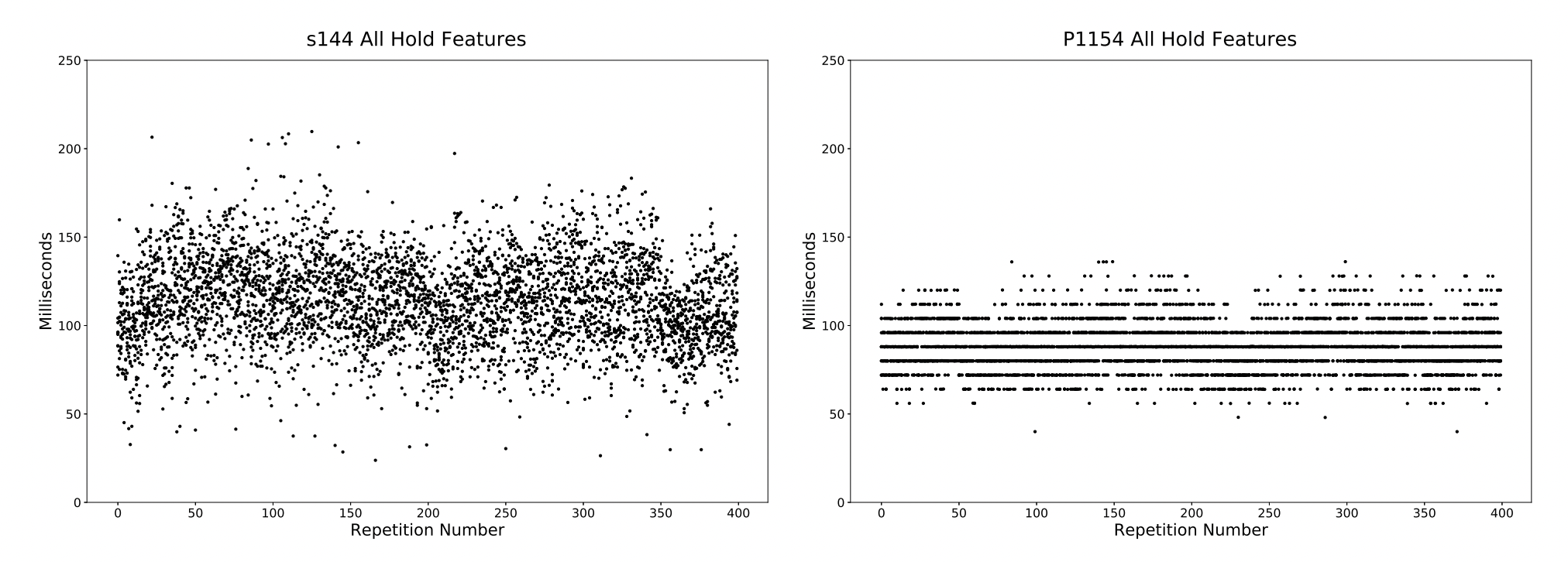
USB keyboards do not report keystrokes immediately upon a keypress. Rather, keystrokes are reported to the computer at a fixed timing interval set by the keyboard. This interval, called the polling interval, is most often a power of two. Since most subjects use USB keyboards, artifacts caused by USB polling are common in field data.
We examined the foremost datasets in the keystroke dynamics community and found that most contained USB polling artifacts, the only exceptions being our own 100-subject and 51-subject lab datasets for which an external timer was used to timestamp keystrokes. A list of datasets that were analyzed is presented below.
| Dataset | Contains USB Polling Artifacts |
|---|---|
| 100-subject Lab | NO |
| 100-subject Field | YES |
| 51-subject Lab | NO |
| GREYC | YES |
| WEBGREYC | YES |
| GREYC-NISLAB | YES |
| KEYSTROKE 100 | YES |
| BIOCHAVES A | YES |
| BIOCHAVES B | YES |
| BIOCHAVES C | YES |
| 136M | YES |
| BEIHANG A | YES |
| BEIHANG B | YES |
Keyboard Change:
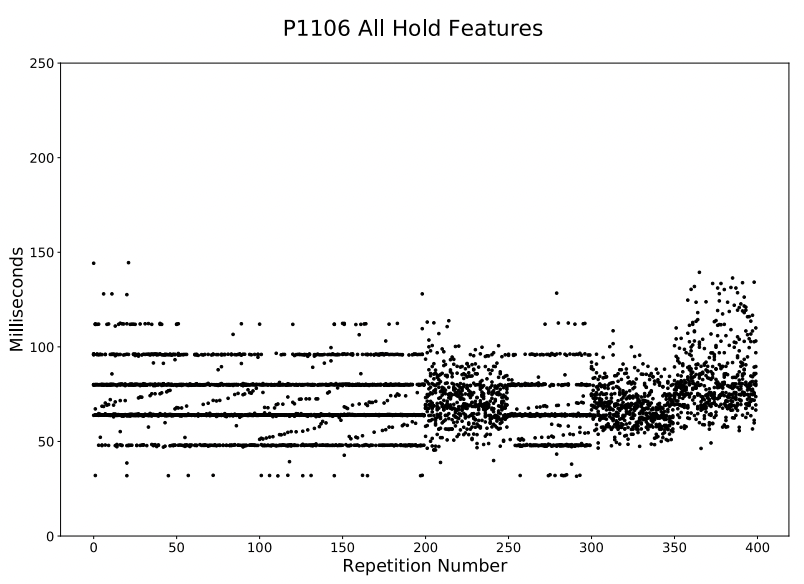
In the field, subjects may change keyboards during the experiment. Different keyboards have different properties: different keyboard matrix scan rates, actuation points, polling intervals, and baud rates to name a few. These differences can cause unpredictable changes in the collected data. In our dataset, these changes typically manifest in a mean shift of the data, change in observed polling interval, or both.
Bursts:
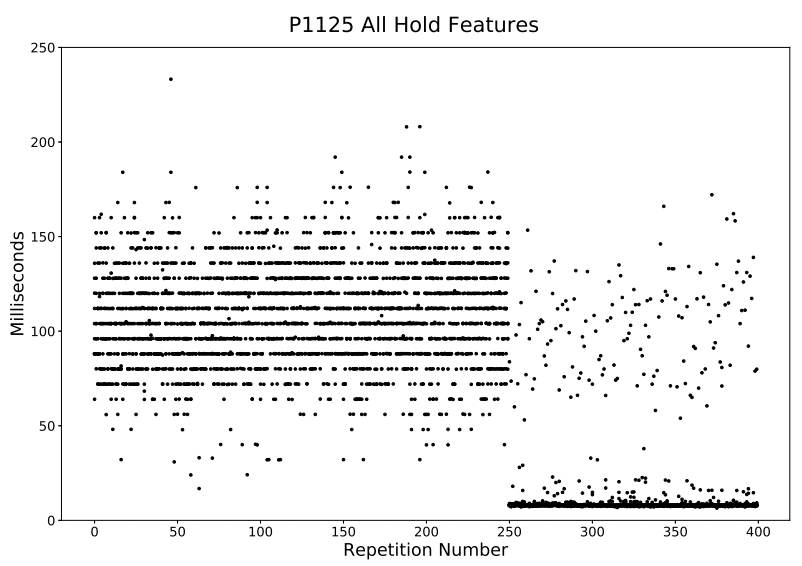
One of the hazards of collecting data in the field is that the processing load on a subject's computer cannot be controlled. In the cases that the processing load is high, input lag may cause many keystrokes to be recorded at once—in a burst. We see some occurrences of this in our field dataset, where many consecutive features are recorded in quick succession, all presenting times of around 0ms.
Ramps:
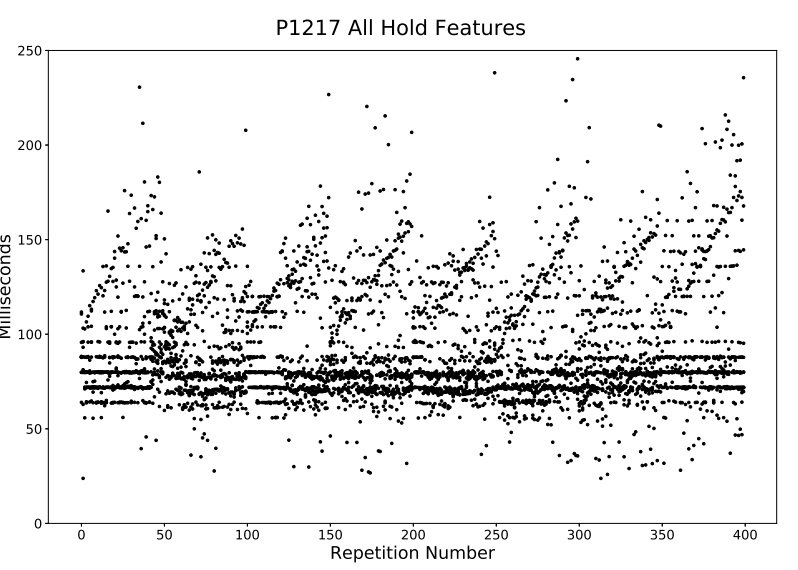
There exist several subjects for whom certain hold features have times that either regularly increase or decrease over the course of a session. The cause of this artifact remains unknown. Perhaps related to this anomaly is a widening gap around 0ms in the up-down latency times for those same subjects. Because the regular increasing/decreasing nature of the data when plotted is reminiscent of a ramp, we call these ramp artifacts.
Common questions:
- Q3-1: Can you tell me what the polling intervals for subjects in your field dataset are?
- Q3-2: Could there be more artifacts, perhaps from other datasets, that are not presented here?
- Q3-3: How can I avoid having these artifacts in my data?
- USB Polling: Have subjects use either PS/2 keyboards or USB keyboards with a low polling interval (such as gaming keyboards).
- Keyboard Change: Ensure that subjects do not change keyboards for the duration of the experiment.
- Bursts: Encourage subjects to close programs running on their computer before contributing data.
- Ramps: Since the cause of the ramps is unknown, we cannot provide any advice on how to avoid them. We encourage researchers to examine their data throughout their experiments to avoid collecting data with ramps.
| Subject | Polling Interval Determined |
|---|---|
| P1102 | 8.0 |
| P1103 | 8.0 |
| P1104 | 8.0 |
| P1107 | 10.0 |
| P1108 | 8.0 |
| P1110 | 8.0 |
| P1111 | 8.0 |
| P1112 | 8.0 |
| P1113 | 8.0 |
| P1114 | 8.0 |
| P1117 | 8.0 |
| P1118 | 8.0 |
| P1123 | 8.0 |
| P1127 | 2.0 |
| P1130 | 8.0 |
| P1131 | 8.0 |
| P1132 | 4.0 |
| P1133 | 8.0 |
| P1134 | 4.0 |
| P1135 | 8.0 |
| P1137 | 8.0 |
| P1144 | 8.0 |
| P1147 | 8.0 |
| P1148 | 8.0 |
| P1150 | 8.0 |
| P1152 | 8.0 |
| P1153 | 8.0 |
| P1154 | 8.0 |
| P1156 | 16.0 |
| P1157 | 8.0 |
| P1158 | 8.0 |
| P1159 | 8.0 |
| P1160 | 8.0 |
| P1162 | 8.0 |
| P1178 | 8.0 |
| P1180 | 4.0 |
| P1181 | 16.0 |
| P1182 | 8.0 |
| P1183 | 4.0 |
| P1188 | 8.0 |
| P1189 | 8.0 |
| P1190 | 8.0 |
| P1191 | 8.0 |
| P1192 | 8.0 |
| P1193 | 16.0 |
| P1195 | 8.0 |
| P1199 | 8.0 |
| P1202 | 8.0 |
| P1204 | 8.0 |
| P1206 | 8.0 |
| P1209 | 16.0 |
| P1210 | 8.0 |
| P1211 | 8.0 |
There are a few steps that can be taken to diminish the effect of some of these artifacts, but many of the confounding factors that are at the source of these artifacts can never be fully eliminated. The only solution, then, is to use an external timer to timestamp keystrokes. If this is not an option, then the following measures may be taken:
4. Lab vs Field Impact on Classification
In our analysis of the foremost datasets in the keystroke dynamics community, we identified USB polling as one of the most common artifacts present in field data. To assess the impact that polling has on classification, we compare the performance of classifiers run on our lab dataset, which contains no artifacts, and the same classifiers run on a degraded version of our lab dataset in order to emulate polling artifacts.
The same evaluation methodology was used for all of the classifiers described here and is the same method presented in our paper at the DSN 2009 conference. We direct readers to that paper for more details on the classifier evaluation methodology.
Polling Effect on Equal-Error Rate:
When evaluating a classifier, we desire a metric to summarize its performance. For the classifiers assessed here, this metric is given as the average equal-error rate (EER). Changes in average EER as the lab dataset is degraded will indicate, at a high level, how the performance of the classifier is affected by polling. We begin the comparison by first establishing a baseline average EER for the classifier. The baseline is the average EER when the classifier is run on the unquantized lab dataset. Then, we compare the baseline to the performance of the classifier on varying degradations of the lab data.
The comparison between the baseline average EER and degraded average EER is standardized through the use of percent error:
percent error = ( abs( baseline - observed ) / baseline ) · 100 .
The advantage of using percent error is that it facilitates comparison between many classifiers that may have different baseline average EERs. The classification results from four of the current top-performing classifiers—a Gaussian Mixture Model (GMM), Mahalanobis Distance Classifier (Mahalanobis), a Mahalanobis KNN (NearestNeighbor), and a Scaled Manhattan Distance Classifier (ScaledManhattan) — for power-of-two polling intervals (since those are the most common) are presented in the table below.
| Classifier | Polling Interval (ms) | Avg EER | Percent Error |
|---|---|---|---|
| GMM | NONE | 0.1044 | 0 |
| GMM | 1 | 0.1047 | 0.2856 |
| GMM | 2 | 0.1047 | 0.3531 |
| GMM | 4 | 0.1059 | 1.4927 |
| GMM | 8 | 0.1085 | 3.9534 |
| GMM | 16 | 0.1115 | 6.8271 |
| GMM | 32 | 0.1195 | 14.4943 |
| Mahalanobis | NONE | 0.1102 | 0 |
| Mahalanobis | 1 | 0.1174 | 6.5105 |
| Mahalanobis | 2 | 0.1166 | 5.7279 |
| Mahalanobis | 4 | 0.1177 | 6.7711 |
| Mahalanobis | 8 | 0.1162 | 5.3627 |
| Mahalanobis | 16 | 0.1218 | 10.4763 |
| Mahalanobis | 32 | 0.1284 | 16.4405 |
| NearestNeighbor | NONE | 0.0999 | 0 |
| NearestNeighbor | 1 | 0.1118 | 11.9006 |
| NearestNeighbor | 2 | 0.1102 | 10.3592 |
| NearestNeighbor | 4 | 0.1103 | 10.4313 |
| NearestNeighbor | 8 | 0.1106 | 10.7302 |
| NearestNeighbor | 16 | 0.1158 | 15.8939 |
| NearestNeighbor | 32 | 0.1237 | 23.8181 |
| ScaledManhattan | NONE | 0.0939 | 0 |
| ScaledManhattan | 1 | 0.0935 | 0.3651 |
| ScaledManhattan | 2 | 0.0939 | 0.0017 |
| ScaledManhattan | 4 | 0.0936 | 0.317 |
| ScaledManhattan | 8 | 0.0958 | 2.0672 |
| ScaledManhattan | 16 | 0.0983 | 4.7347 |
| ScaledManhattan | 32 | 0.1027 | 9.4087 |
Polling Effect on Subject Misclassifications:
The full impact of polling on classification is not revealed solely by examining performance metrics. The subjects who are misclassified by the classifier are also prone to change due to the effects of polling. For a complete treatment of the effect of polling on misclassification, we refer readers to our paper. Here, we provide an example of what can change when only one subject in the dataset provides data with polling artifacts:
s040 after adding an 8ms polling interval to their data:
- Before polling, 151 of testing vectors from s040 were correctly classified. After polling, only 131 of testing vectors from s040 were correctly classified.
- 46 subjects were classified differently by s040's detector after polling artifacts were added to their data.
- After polling, 17 subjects were misclassified as s040 who were not misclassified before. In an actual biometric system, this would mean 17 people were falsely accused of breaking into s017's account.
Common questions:
- Q4-1: How was the lab data degraded?
- The user presses a key down at t = 1ms. The computer will not record the keydown until t = 8ms -- the time of the next poll. Then, at time t = 16ms, the user releases the key. Since the key was released on a multiple of 8, the computer registers the keyup at t = 16ms. The user's actual hold time was 15ms, but the computer registered your hold time as 8ms. This is a situation where the computer recorded a hold time that was less than the user's actual hold time due to polling.
- The user presses the key down at t = 8ms. The computer will record the keydown at t = 8ms because it is a multiple of the polling interval. Then, at time t = 17ms, the user releases the key. Since the user did not release the key on a multiple of the polling interval, the computer registers the keyup at t = 24ms -- the next multiple of the polling interval. The user's actual hold time was 9ms, but the computer registered their hold time as 16ms. This is a situation where the computer recorded a hold time that was greater than the user's actual hold time due to polling.
- Q4-2: How do I interpret the table of classification results?
- Q4-3: Why do you use the average equal-error rate as the sole measure of performance?
lo = δ · round( hi / δ )
A round-to-even rounding policy was used to avoid the possible confound of biasing the data. In addition to being unbiased, a round-to-even is representative of data collected over USB. Consider the following scenarios for a polling interval of 8ms -- meaning the computer collects keystrokes from the keyboard buffer every 8ms. All times are absolute (starting from time t = 0) and each scenario is equally likely:
The second column presents the polling interval to which the lab dataset was degraded before the detector was run. For example, a value of 8 in this column indicates that the lab dataset was degraded to emulate a polling interval of 8ms for all subjects.
The third column provides the average equal-error rate of each detector, as estimated by the evaluation methodology in the DSN 2009 paper.
The fourth column presents the percent error between the average equal-error rate in the third column and the baseline average equal-error rate for that detector (the average equal-error rate with no polling). Lower values for percent error indicate that a detector is more robust against polling artifacts in the dataset.
Note that these results are only the observed results of a single evaluation on a single data set. We would discourage a reader from inferring that the better-performing detectors are necessarily going to always outperform the other detectors. We believe it is likely that many factors—who the subjects are, what they type, and specifically how the data are collected and analyzed—affect the error rates of anomaly detectors used for keystroke dynamics. Variations in these factors might change a detector's equal-error rate, and might cause a different set of detectors to be among the top performers. A low percent error in this table suggests that a detector is promising; but more data, and more evaluations will be needed to determine how various factors affect keystroke-dynamics error rates. This topic is a subject of our current and ongoing research.